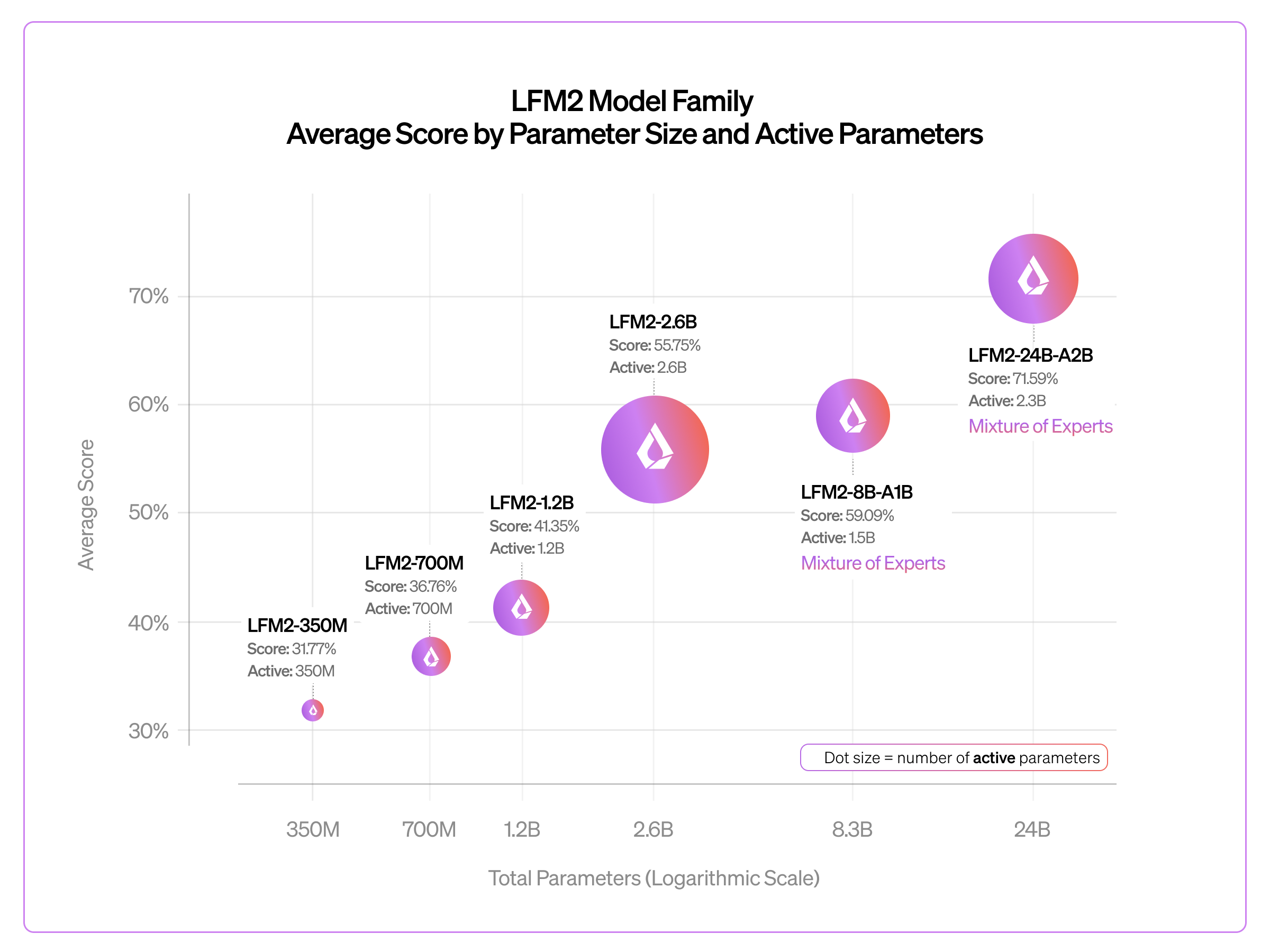
Liquid AI has released an early checkpoint of its LFM2-24B-A2B model, a sparse Mixture of Experts (MoE) architecture with 24 billion total parameters and 2 billion active parameters per token. This model demonstrates that the LFM2 architecture effectively scales to larger sizes, with consistent quality gains observed across benchmarks as the family has grown. Designed to fit within 32GB of RAM, LFM2-24B-A2B is intended for deployment on both cloud and edge environments, including consumer laptops and desktops. AI
IMPACT Provides an edge-deployable MoE model that balances parameter count with active parameters for efficient inference.
RANK_REASON Release of an open-weight model with detailed architecture and benchmark information, but not from a top-tier frontier lab.
Read on Hacker News — AI stories ≥50 points →
- gpt-oss-20b
- Hugging Face
- LFM2
- LFM2-24B-A2B
- llama.cpp
- Mixture of Experts
- Qwen3-30B-A3B-Instruct-2507
- Liquid AI
AI-generated summary · Google Gemini · from 3 sources. How we write summaries →