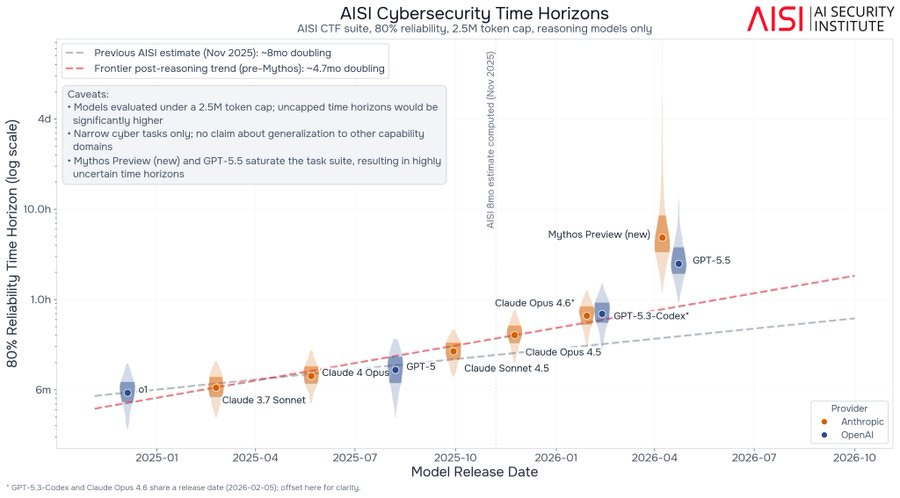
While # AI can in theory copy themselves to escape control, they are not yet able to do so: https://www. theguardian.com/technology/202 6/may/07/no-one-has-done
A recent study indicates that while artificial intelligence theoretically possesses the capability to replicate itself and evade human control, this has not yet been observed in practice. Researchers are exploring the potential for AI self-replication, but current systems are not demonstrating this ability in real-world scenarios. AI
IMPACT While AI self-replication is not currently a reality, ongoing research into this area is crucial for future AI safety and control.












![Africa: Rachel Ruto Leads African Call for Protection of Children in Ai-Driven Digital World At Africa Forward Summit: [Capital FM] Nairobi -- First Ladies from](https://cdn.fosstodon.org/cache/media_attachments/files/116/565/593/924/175/755/original/9b7c95293d05557e.png)


