Fastino Labs Open-Sources GLiGuard: A 300M Parameter Safety Moderation Model That Matches or Exceeds Accuracy of Models 23–90x Its Size
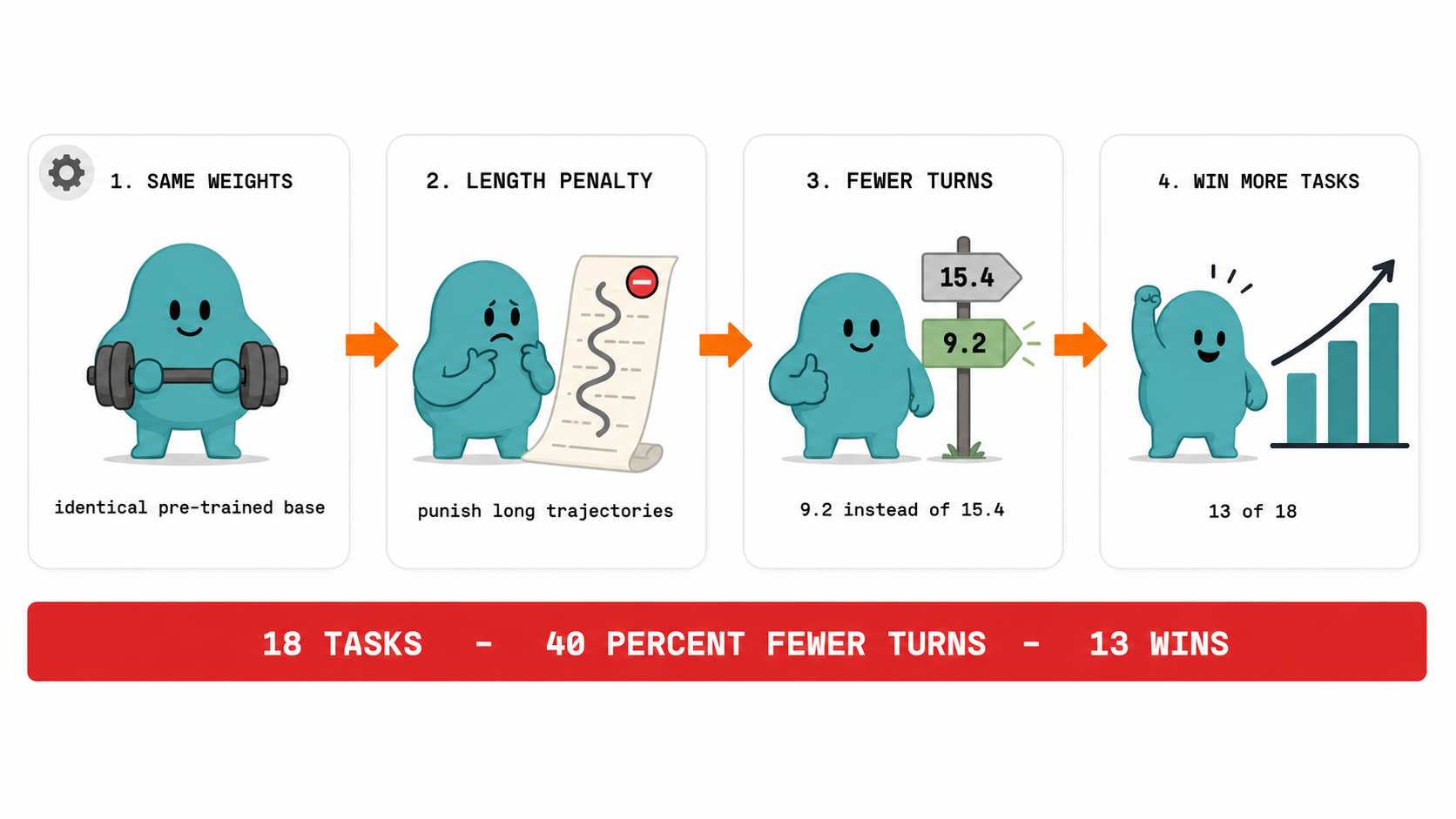
Fastino Labs has released GLiGuard, an open-source safety moderation model designed to be significantly faster and more efficient than existing solutions. Unlike traditional decoder-only models that generate responses token by token, GLiGuard uses an encoder-based architecture to classify prompts and responses in a single pass. This approach allows it to match or exceed the accuracy of much larger models while operating up to 16 times faster, addressing the growing cost and latency issues associated with LLM safety moderation. AI

IMPACT Offers a more efficient and faster alternative for LLM safety moderation, potentially reducing operational costs for AI applications.