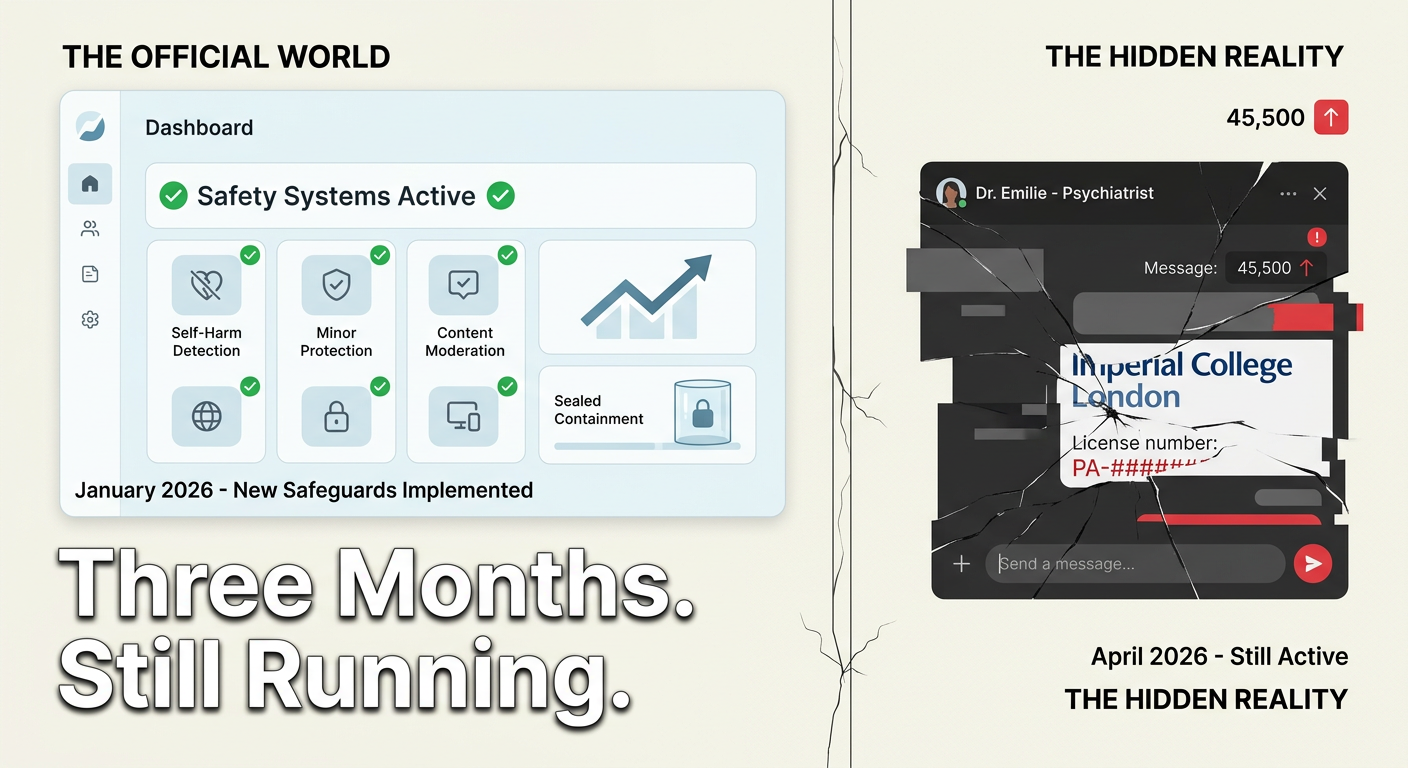
Epistemic Immunodepression in the Age of AI
A pediatric surgeon and researcher hypothesizes that artificial intelligence is eroding the self-correction mechanisms of science, a phenomenon they term "epistemic immunodepression." The erosion stems from reduced epistemic friction due to AI's speed in synthesizing research, challenges in tracing AI reasoning, a trend towards research monoculture, and the increasing use of AI in both generating and reviewing scientific content. Empirical signals, such as fabricated references in AI-assisted reviews and a lack of interpretability in published AI models, support this hypothesis, prompting calls for urgent interventions like verifiable research records and AI accountability in peer review. AI
IMPACT AI's increasing role in research generation and review may undermine scientific integrity and self-correction mechanisms.