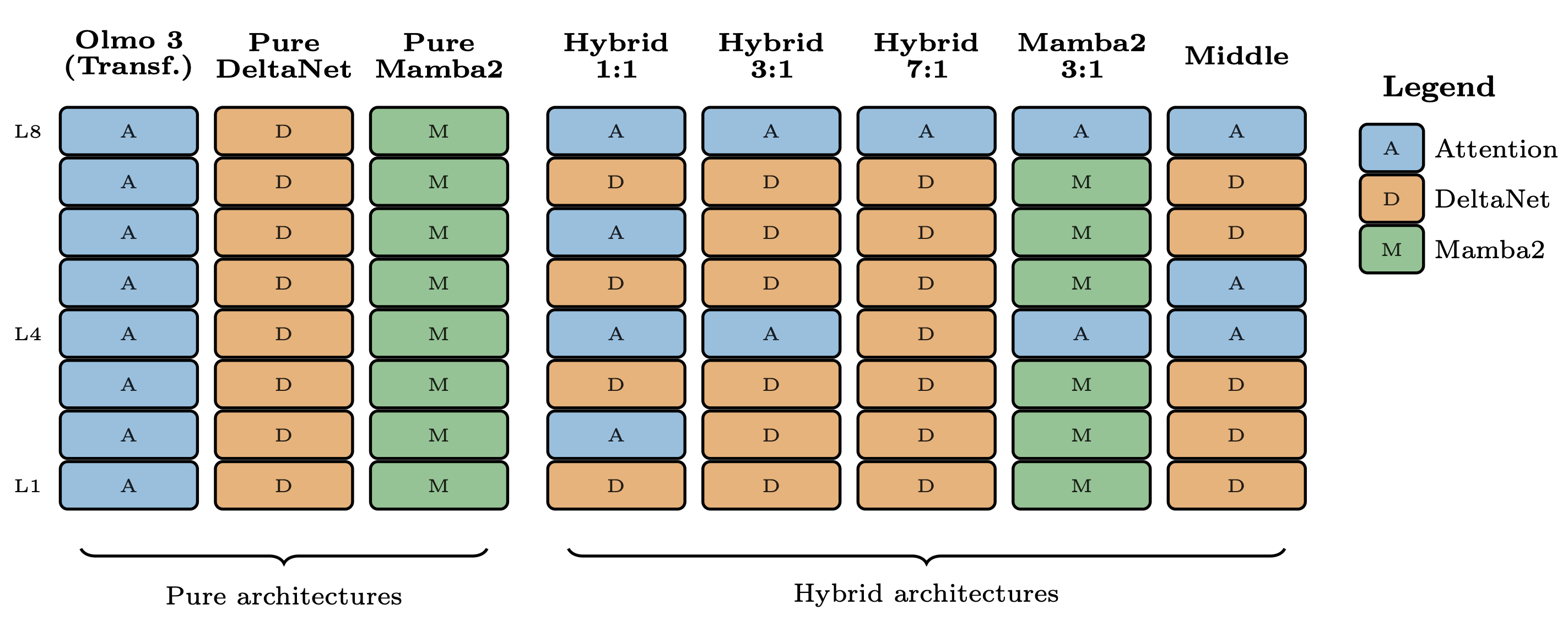
The Olmo Hybrid model, a new 7B parameter open-source language model, has been released, featuring a hybrid architecture that combines traditional attention mechanisms with recurrent neural network (RNN) modules like Gated DeltaNet (GDN). This approach aims to improve computational efficiency by compressing information into a hidden state, thereby avoiding the quadratic cost associated with standard transformer attention. The release includes a research paper detailing the theoretical advantages and empirical evidence of hybrid models, demonstrating their potential for better token efficiency compared to pure transformer architectures. AI
Summary written by None from 1 source. How we write summaries →
RANK_REASON Release of an open-source model with accompanying research paper exploring novel architectural approaches.