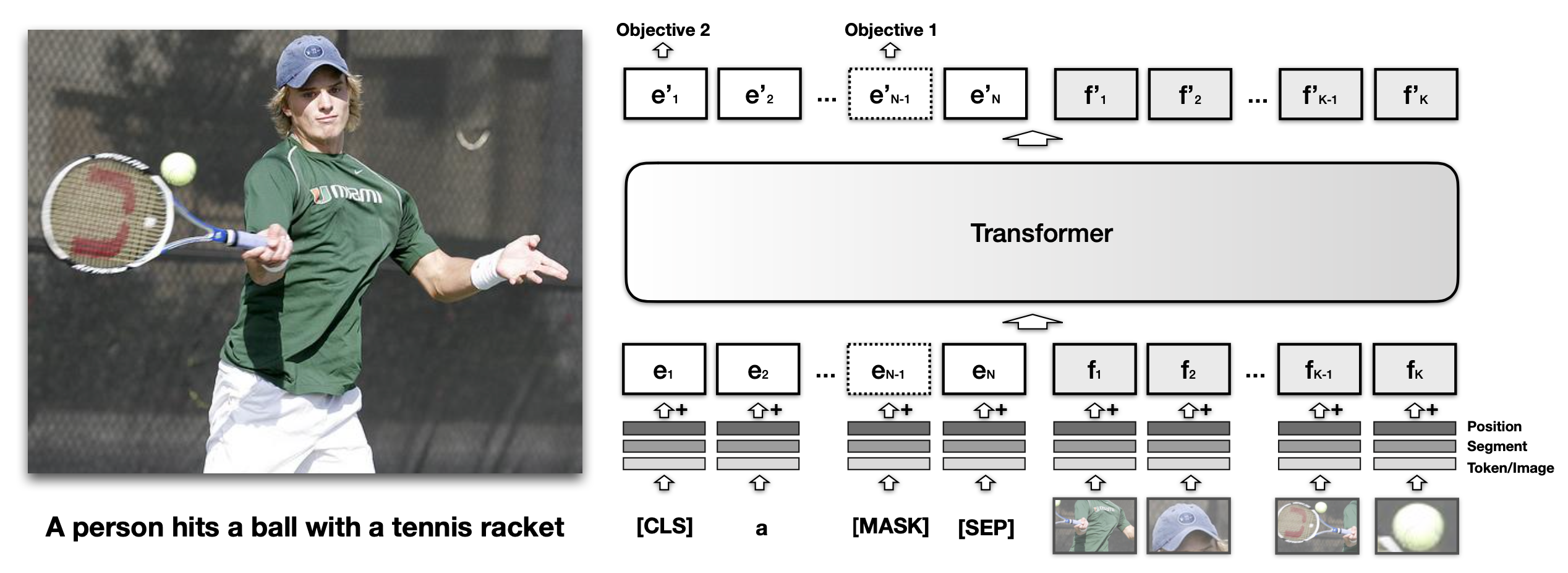
Lilian Weng's blog post details the evolution of generalized language models, focusing on how they are extended to process visual information. Early approaches like VisualBERT fused image patches with text tokens, using self-attention to align visual and textual data for tasks such as image captioning. More recent models like SimVLM treat encoded images as prefixes for language models, leveraging large datasets for pre-training. These methods aim to create unified models capable of understanding and generating content across both visual and textual modalities. AI
Summary written by gemini-2.5-flash-lite from 2 sources. How we write summaries →
RANK_REASON The cluster summarizes research papers and blog posts detailing advancements in generalized visual language models.