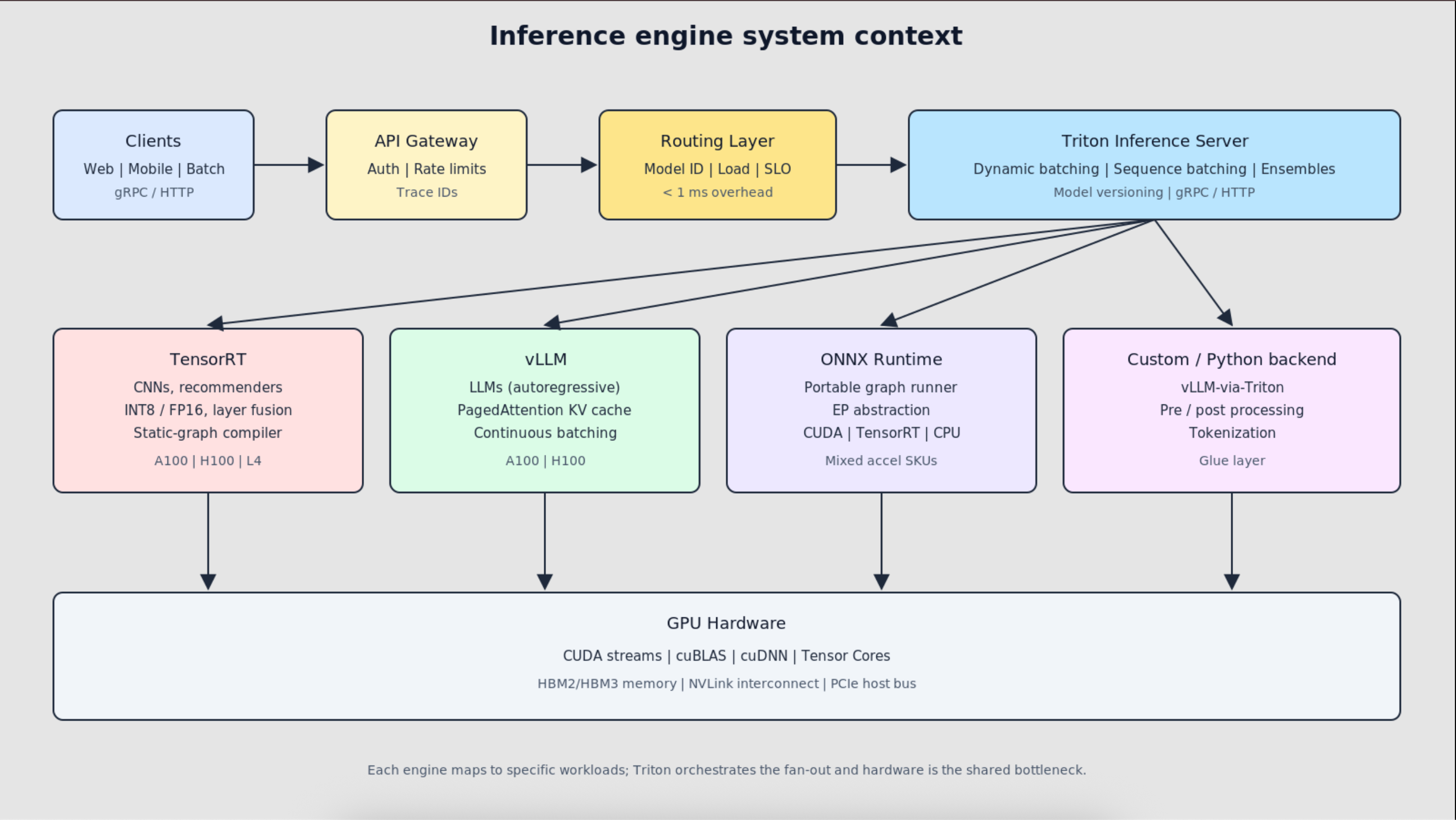
This article compares four key GPU inference frameworks: NVIDIA's TensorRT, vLLM, Triton, and ONNX Runtime. It delves into their architectures, performance characteristics, and suitability for different large language model (LLM) deployment scenarios. The author, a Principal Engineering Manager at Microsoft, aims to guide practitioners in selecting the optimal stack for their specific inference needs. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Provides guidance on optimizing LLM deployment, impacting AI operators focused on inference performance.
RANK_REASON Article provides a comparative analysis of existing inference frameworks, not a new release or significant industry event.