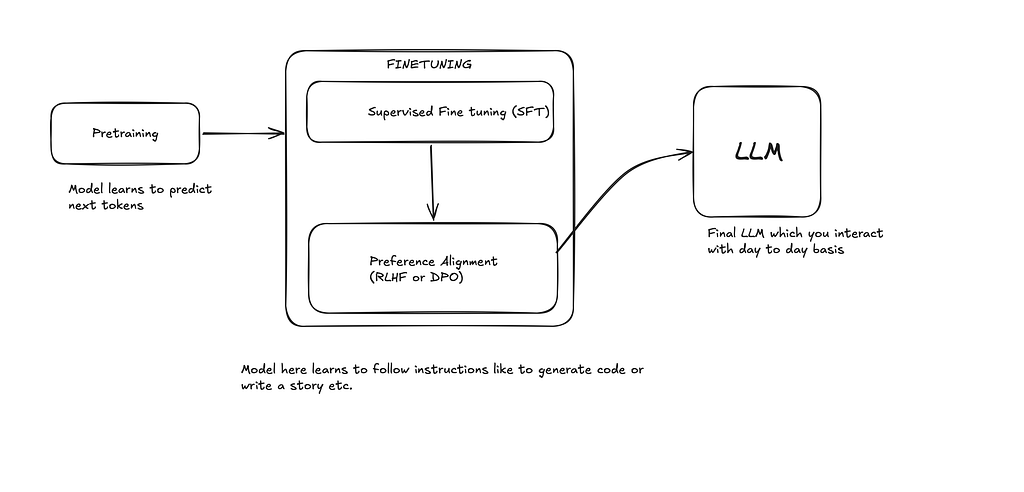
This blog post explains the process and necessity of fine-tuning large language models (LLMs) for specific tasks. It differentiates fine-tuning from Retrieval-Augmented Generation (RAG), stating that fine-tuning is best for altering model behavior or reasoning, while RAG is for incorporating external or frequently changing knowledge. The post details Supervised Fine-Tuning (SFT), which uses instruction-answer pairs to train models, and provides examples of data preparation for SFT, including generating synthetic datasets with other LLMs. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Provides a foundational understanding of LLM fine-tuning techniques, crucial for adapting models to specific applications.
RANK_REASON Blog post explaining technical concepts and methods related to LLM fine-tuning. [lever_c_demoted from research: ic=1 ai=1.0]