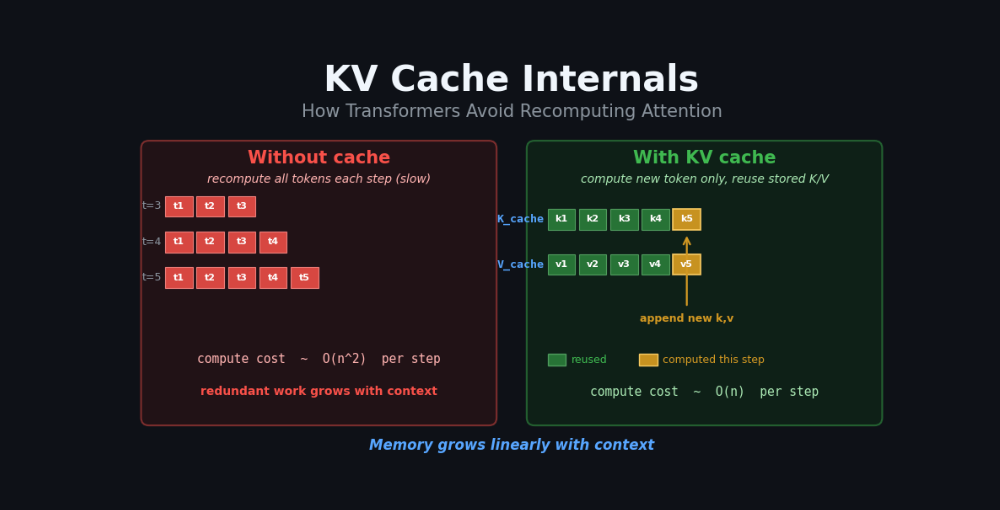
This article delves into the internal workings of KV cache, a crucial mechanism that enables transformer models to avoid redundant computations during attention calculations. It explains how this technique optimizes the generation of sequential tokens by storing and reusing previously computed key and value states. The explanation highlights the efficiency gains achieved by preventing repeated calculations for each new token. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Explains a core optimization technique for transformer models, improving understanding of their efficiency.
RANK_REASON The article explains a technical mechanism within AI models. [lever_c_demoted from research: ic=1 ai=1.0]