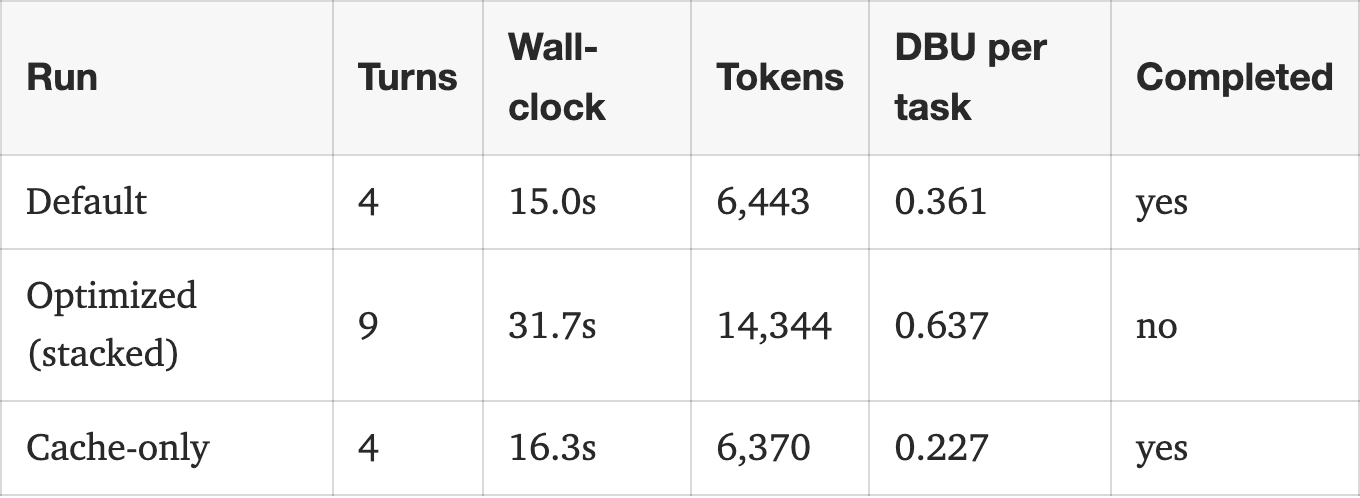
The author explored methods to optimize token usage in large language models, specifically within the Databricks environment. They found that while combining three token-saving patterns initially doubled token consumption, implementing caching strategies effectively mitigated this increase. The experiments focused on practical application and efficiency within a specific platform. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Demonstrates practical techniques for reducing operational costs in LLM deployments.
RANK_REASON The cluster describes an experiment and findings related to optimizing LLM token usage, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]