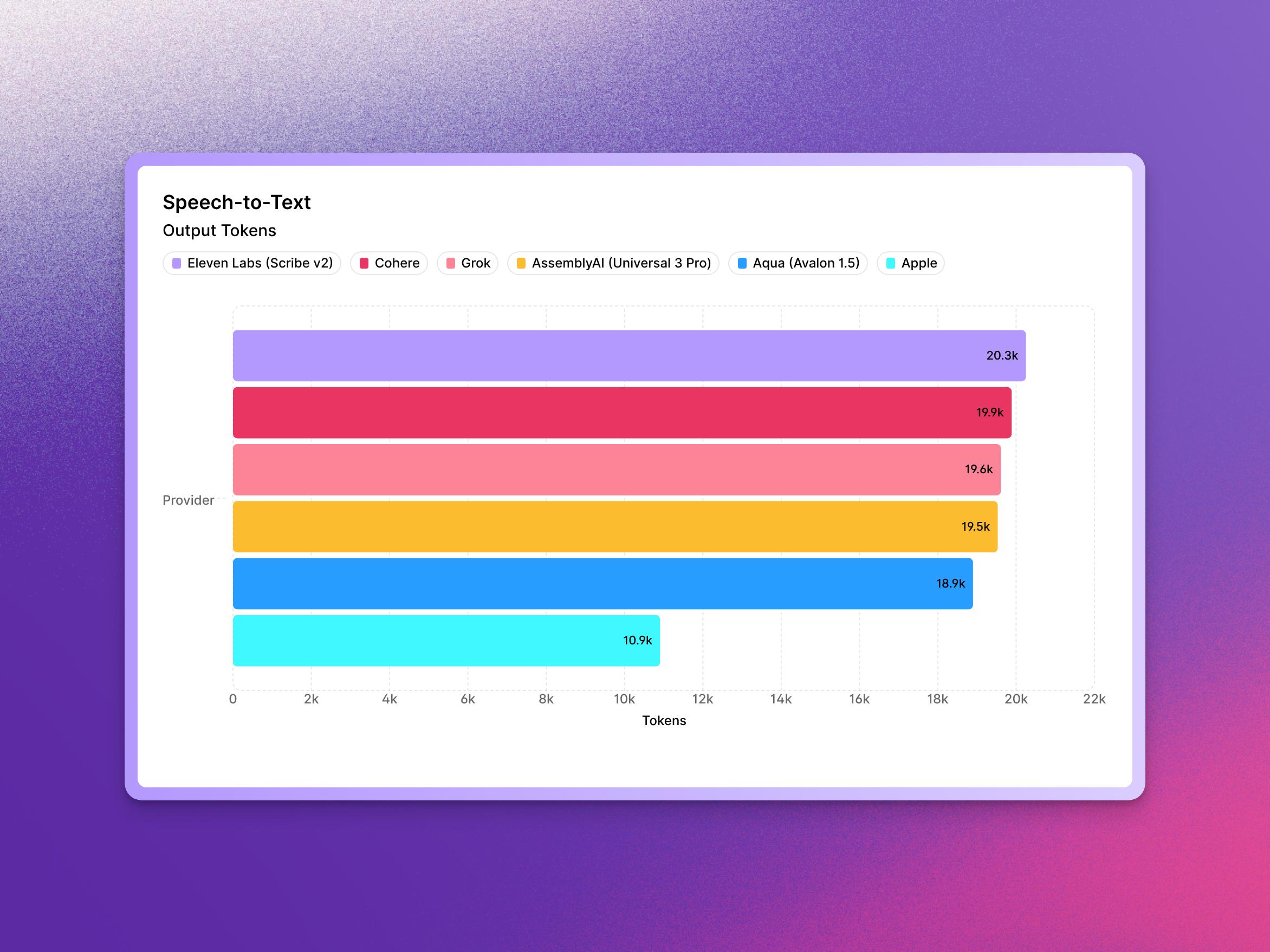
A recent comparison of speech-to-text models highlights Eleven Labs' Scribe v2 as the top performer with a score of 20,251. Cohere's model followed closely at 19,885, with Grok achieving 19,611. AssemblyAI's Universal 3 Pro scored 19,530, while Aqua's Avalon 1.5 reached 18,899. Apple's local model was also included, scoring 10,907. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Provides a benchmark for speech-to-text model performance, useful for developers choosing STT solutions.
RANK_REASON This is a comparison of speech-to-text models, not a release of a new frontier model or a significant industry event.