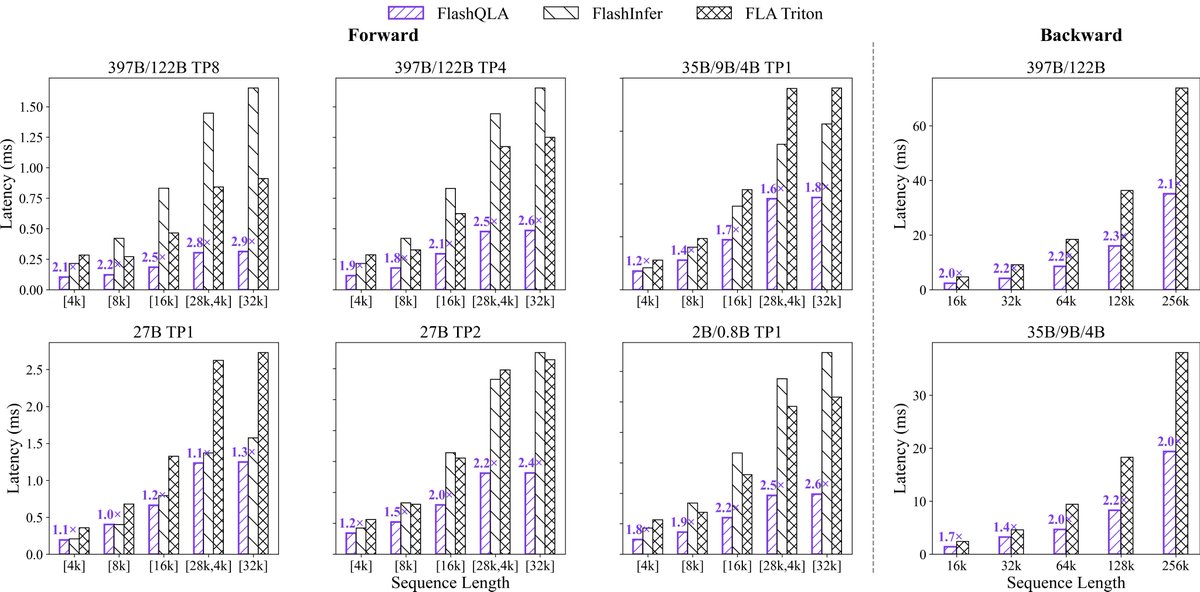
Alibaba's Qwen team has released FlashQLA, a new set of high-performance linear attention kernels developed using TileLang. These kernels are designed to improve the efficiency of attention mechanisms in large language models. The team also shared benchmark results for their Qwen models, showcasing performance across various configurations. AI
Summary written by gemini-2.5-flash-lite from 3 sources. How we write summaries →
IMPACT Introduces optimized kernels that could improve LLM inference speed and efficiency.
RANK_REASON Release of new high-performance kernels and benchmark results for an existing model family.