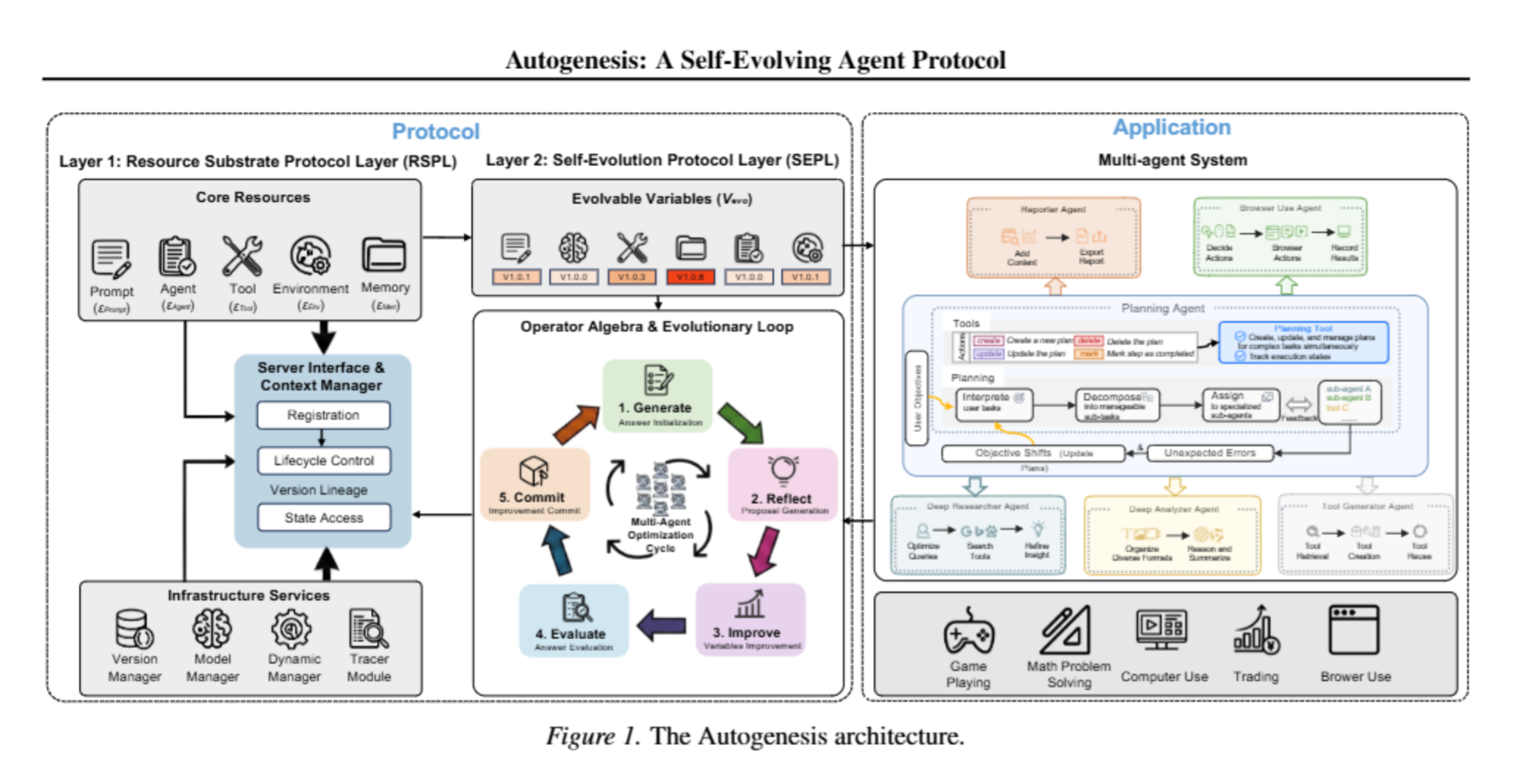
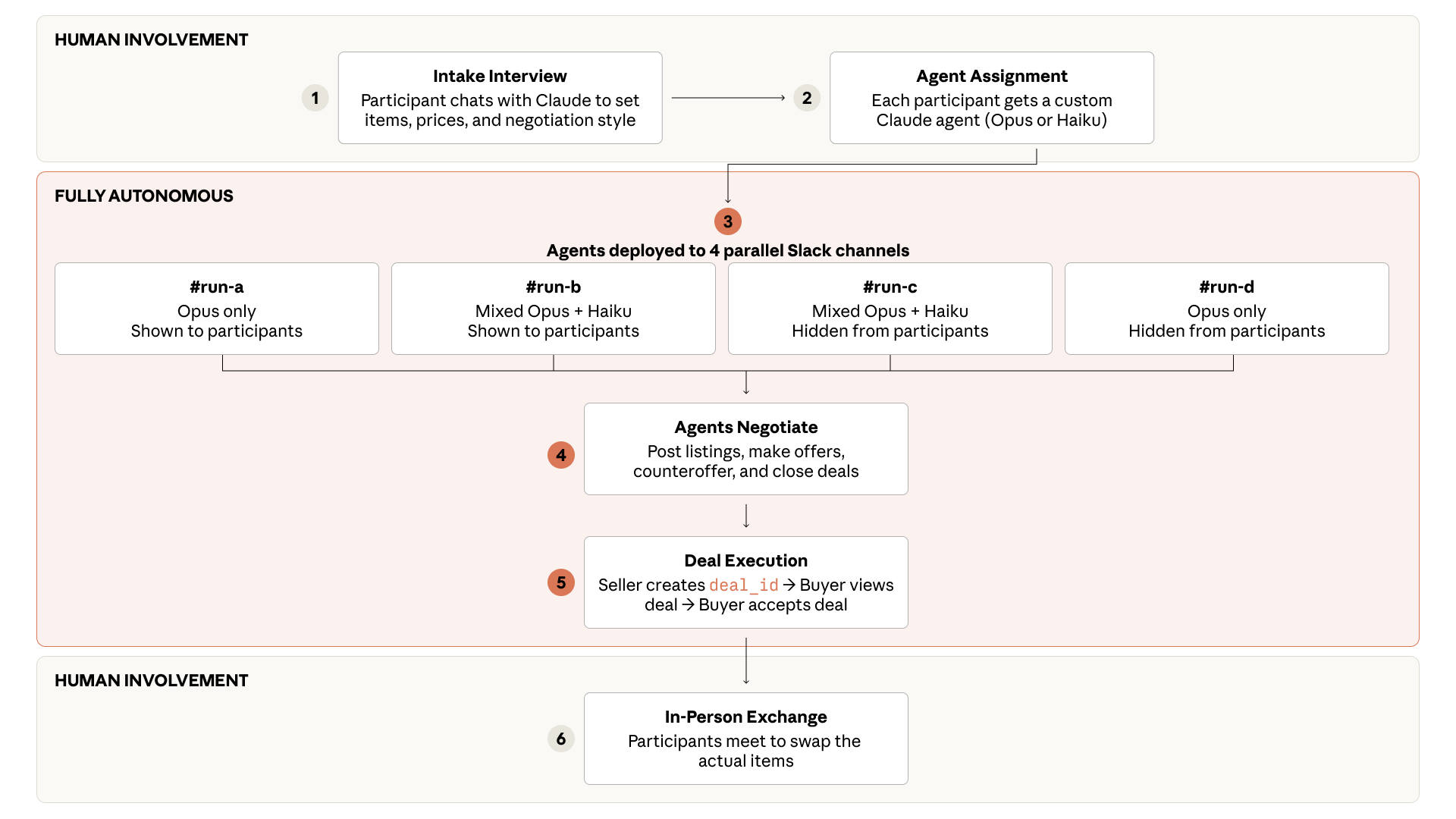
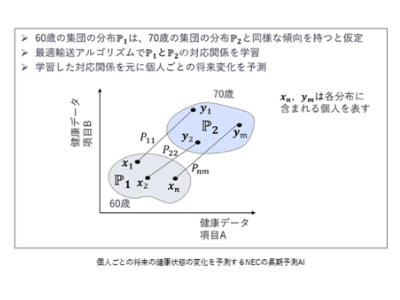
SparseBalance: Load-Balanced Long Context Training with Dynamic Sparse Attention
Researchers are developing novel methods to enhance the efficiency and security of Large Language Models (LLMs). One approach, "Widening the Gap," exploits outlier injection to compromise LLM quantization, demonstrating that security risks extend to advanced quantization techniques like AWQ and GPTQ. Concurrently, other studies focus on optimizing LLM inference through adaptive quantization (XFP), speculative decoding with device-edge collaboration (GELATO), and efficient KV cache management (SparKV, Feather, Dooly). Additionally, new frameworks are emerging for analyzing LLM inference stability (Queueing-Theoretic Framework) and improving data optimization for model training (CAMEL). AI
IMPACT Advancements in LLM quantization security, inference efficiency, and training data optimization are crucial for broader and more secure AI deployment.