The first two custom silicon chips designed by Microsoft for its cloud
Microsoft has developed its own custom AI chips, the Azure Maia 100 AI accelerator and the Azure Cobalt 100 CPU, to power its Azure cloud infrastructure. These in-house designed chips aim to reduce reliance on third-party providers like Nvidia and optimize performance and cost for AI workloads, including training and inference for large language models. The Maia chip is being developed in collaboration with OpenAI, with CEO Sam Altman highlighting its potential to make model training more capable and affordable. AI
IMPACT Microsoft's custom silicon for Azure aims to reduce AI training costs and improve performance, potentially impacting cloud infrastructure economics.









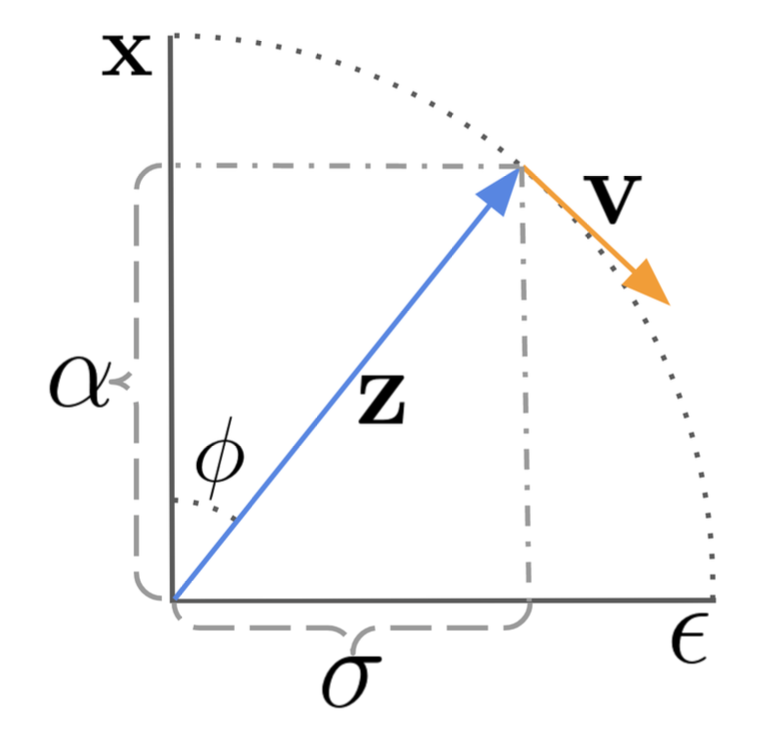

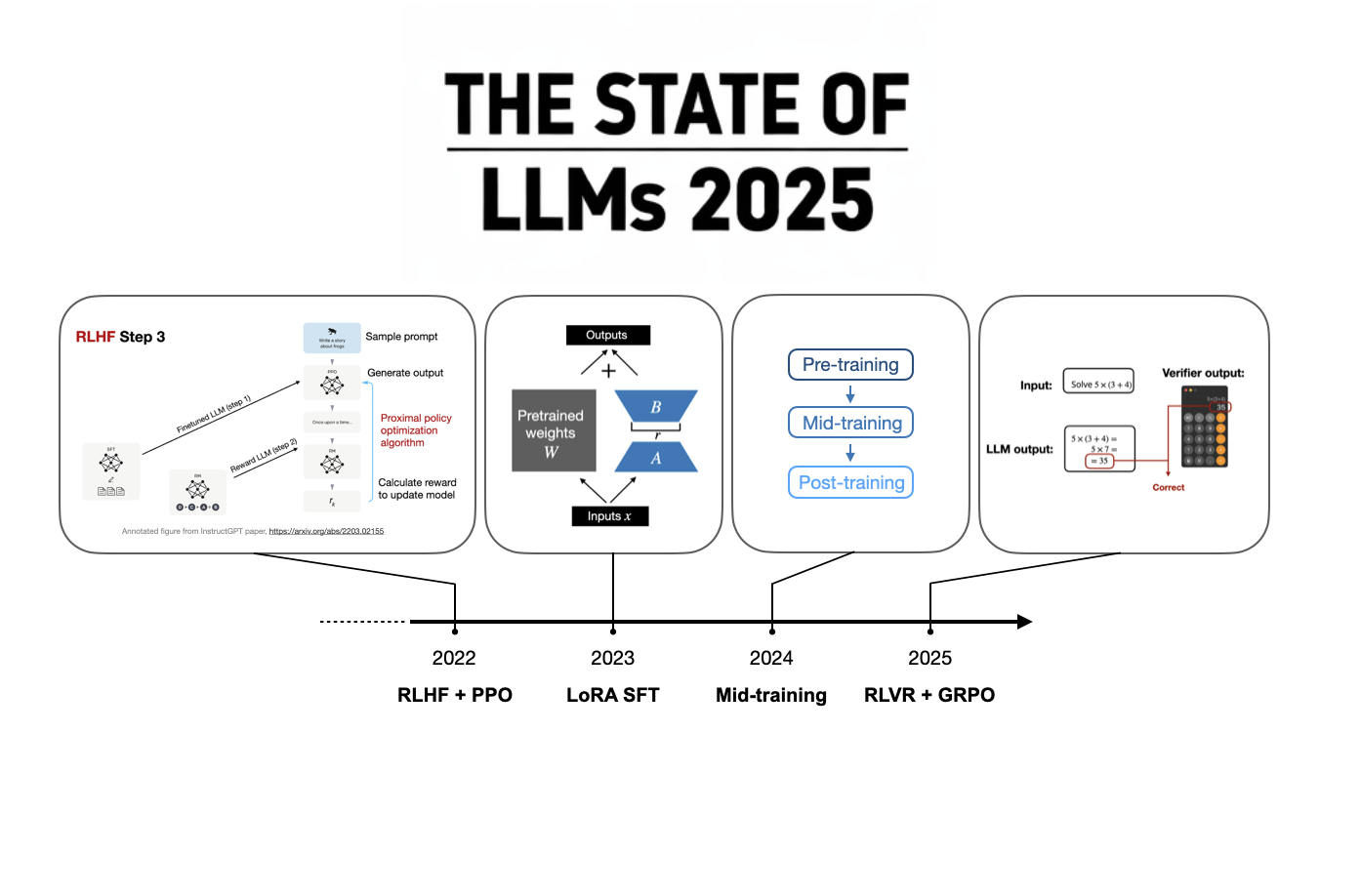
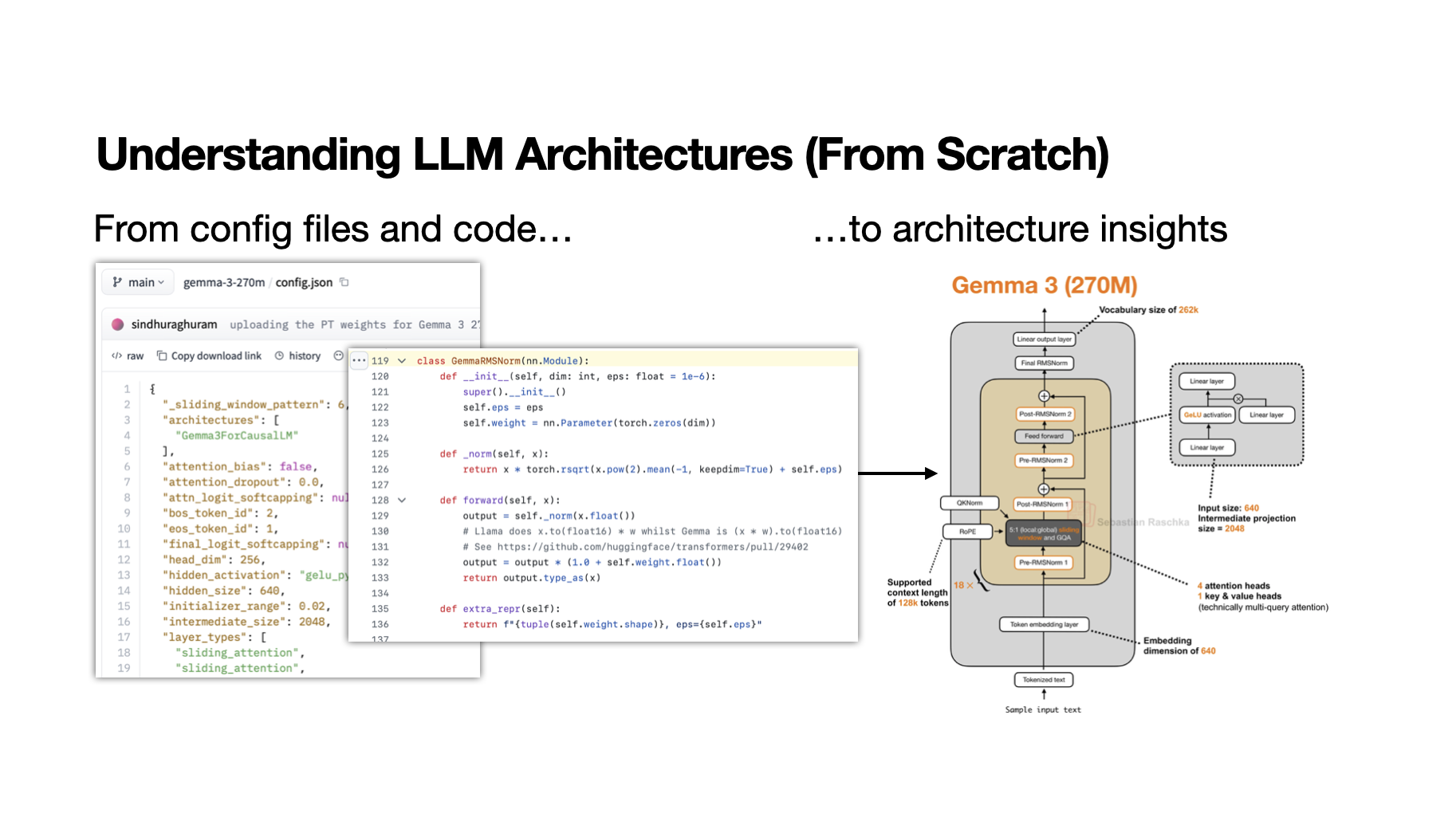




![[GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://i3.ytimg.com/vi/bAWV_yrqx4w/hqdefault.jpg)