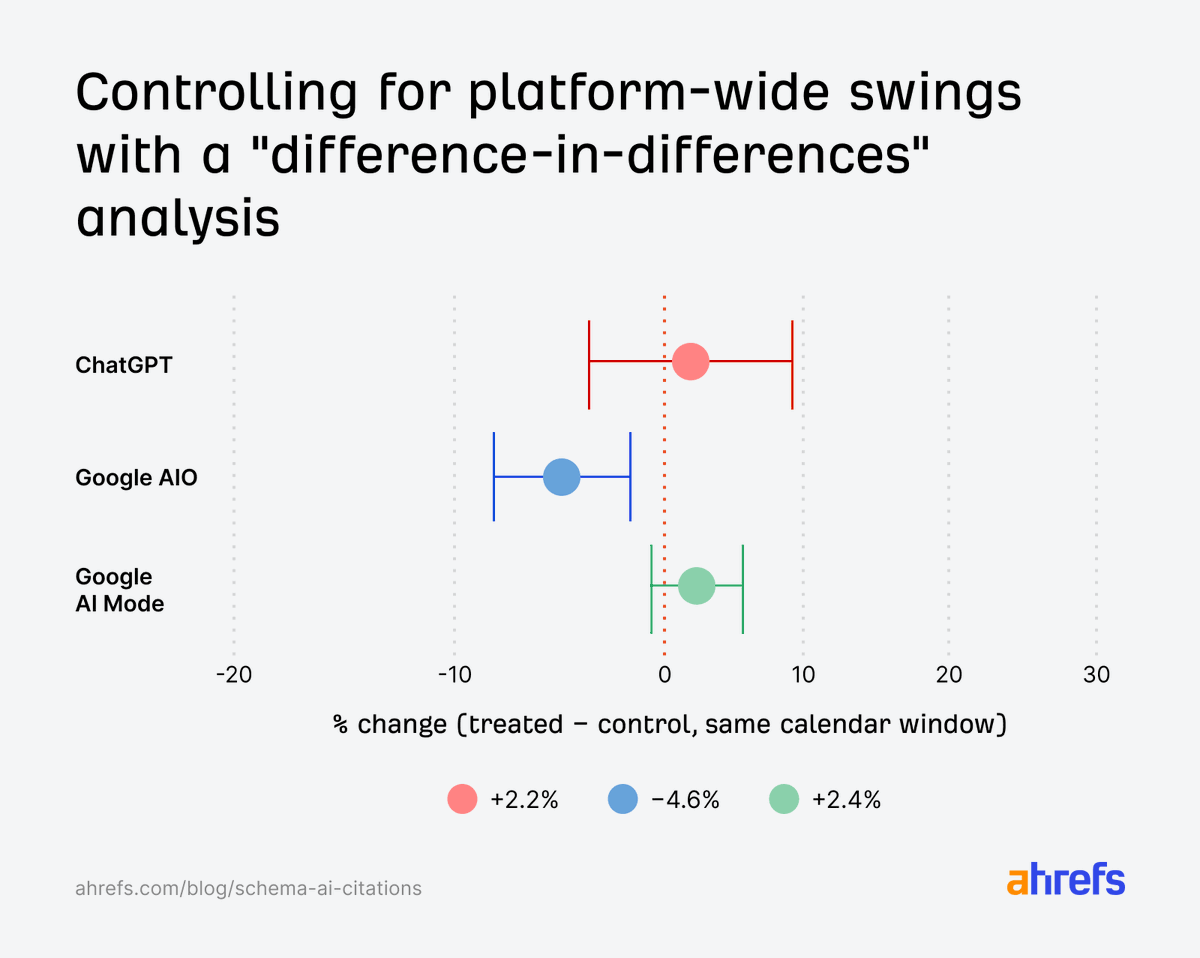
The Gordian Knot for VLMs: Diagrammatic Knot Reasoning as a Hard Benchmark
Researchers have introduced KnotBench, a new benchmark designed to test the diagrammatic reasoning capabilities of vision-language models (VLMs). The benchmark utilizes a large corpus of knot diagrams and tasks that assess equivalence, move prediction, identification, and cross-modal grounding. Current leading models like Claude Opus 4.7 and GPT-5 show significant limitations, often performing at or near random chance on many tasks, indicating a gap between visual perception and operational understanding of these structures. AI
IMPACT Highlights significant limitations in current VLMs' ability to perform complex diagrammatic reasoning, suggesting a need for new architectures or training methods.