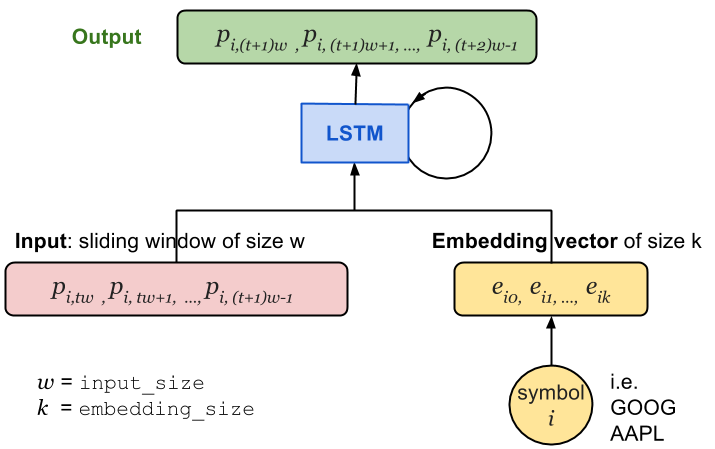
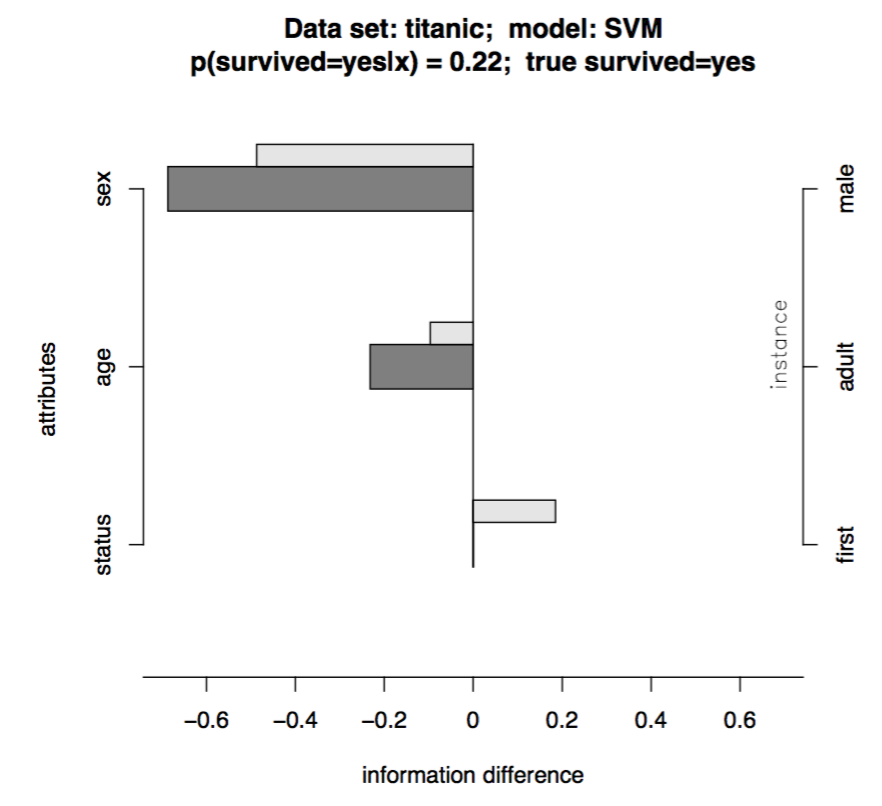
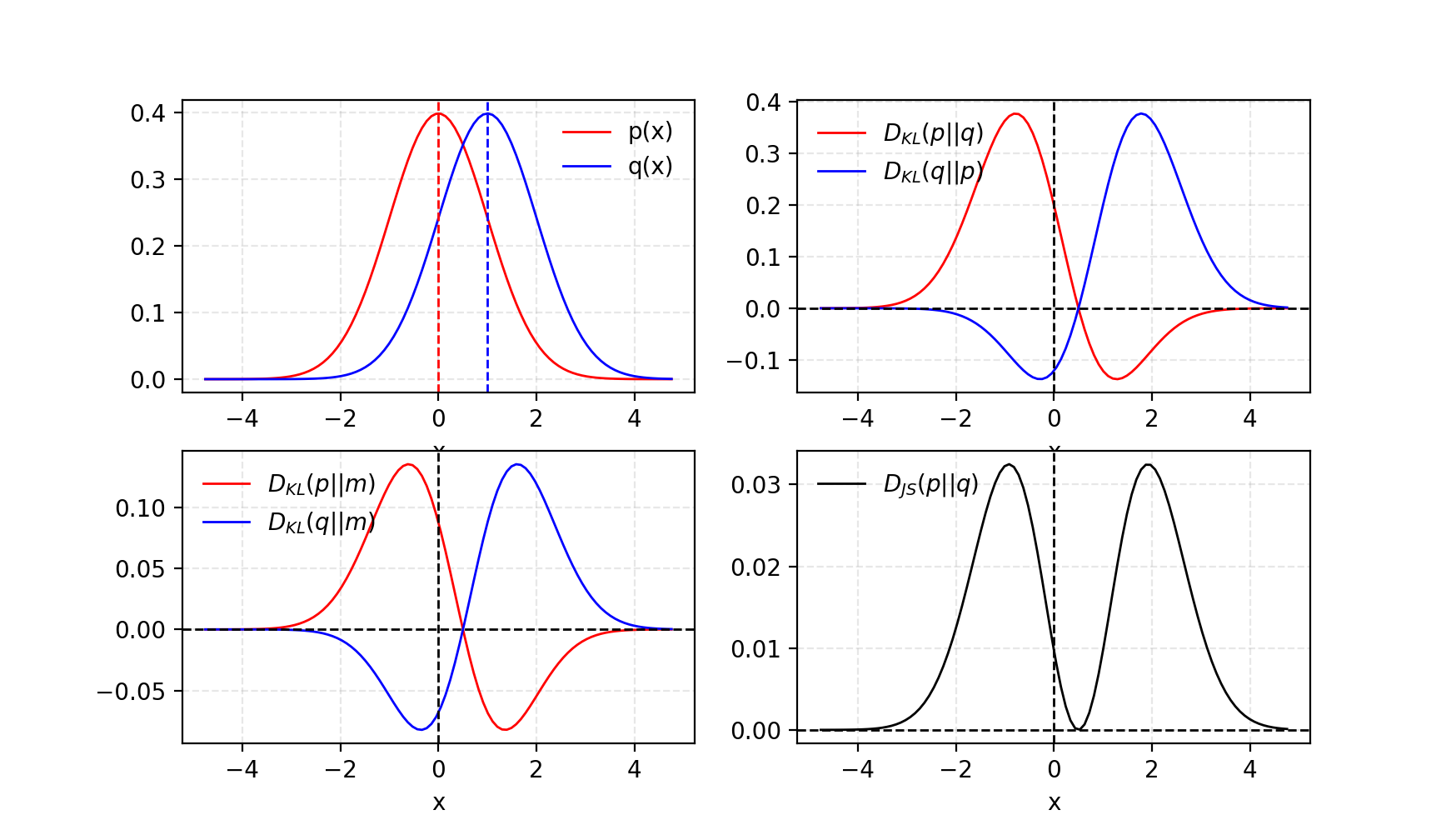
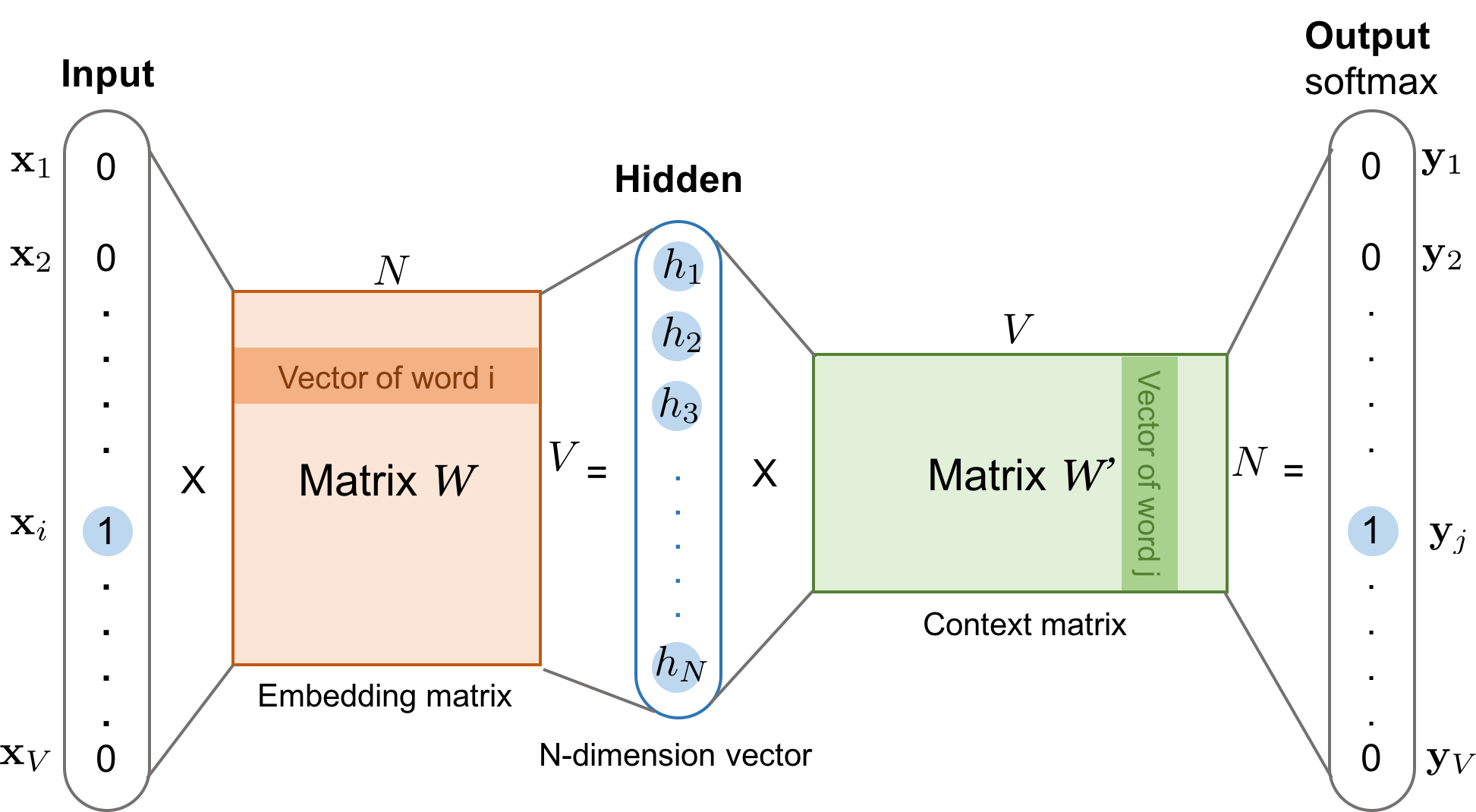
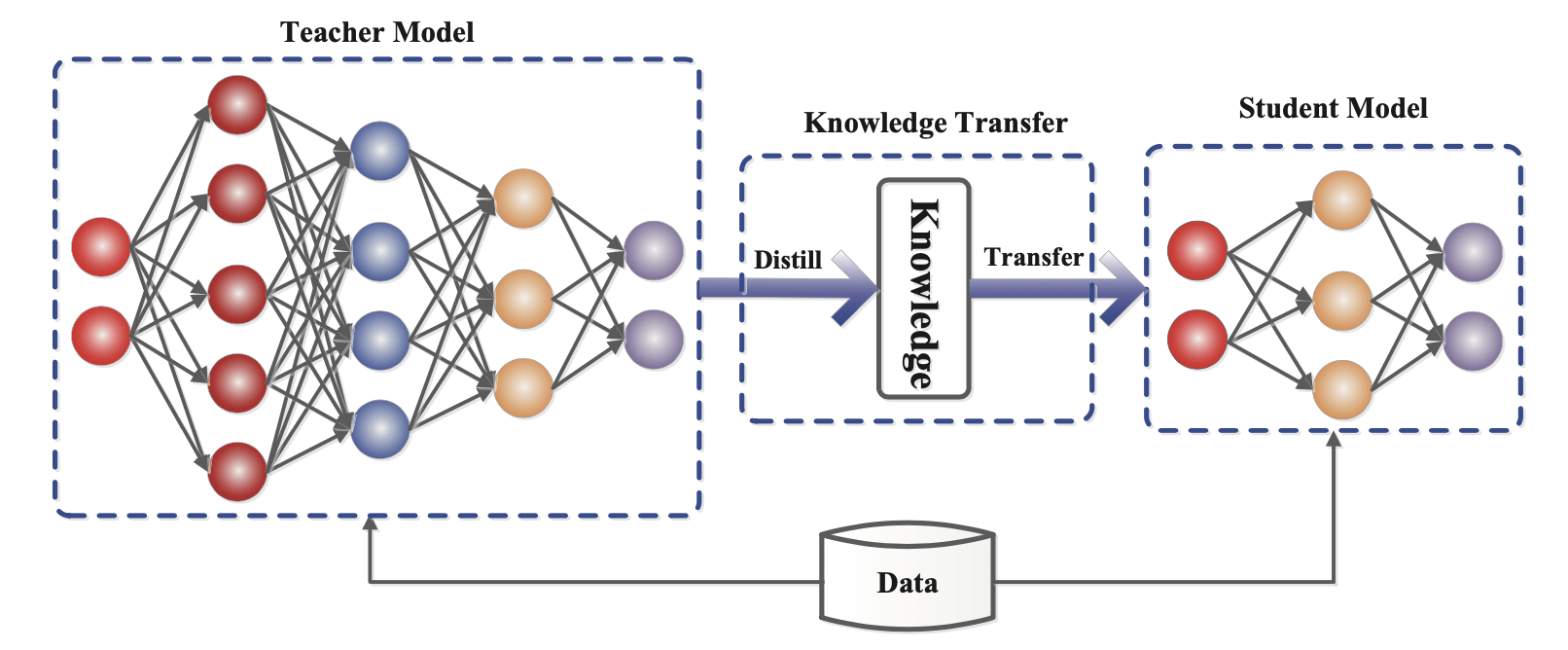
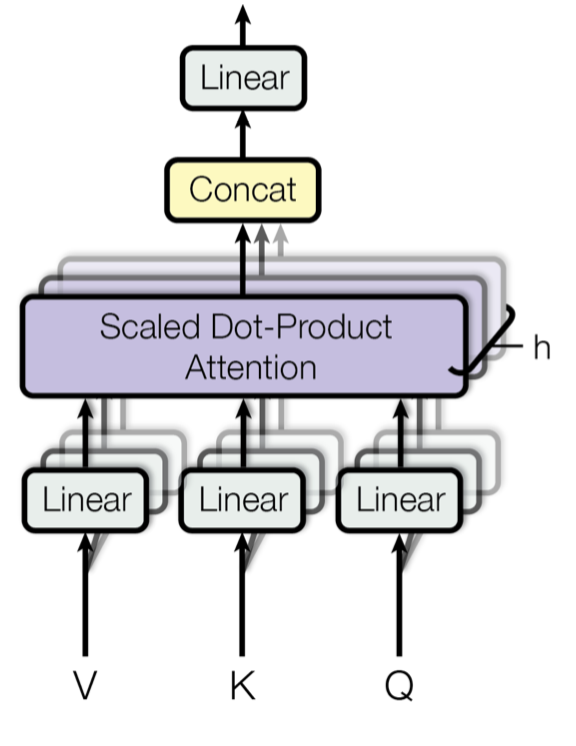
AI and compute
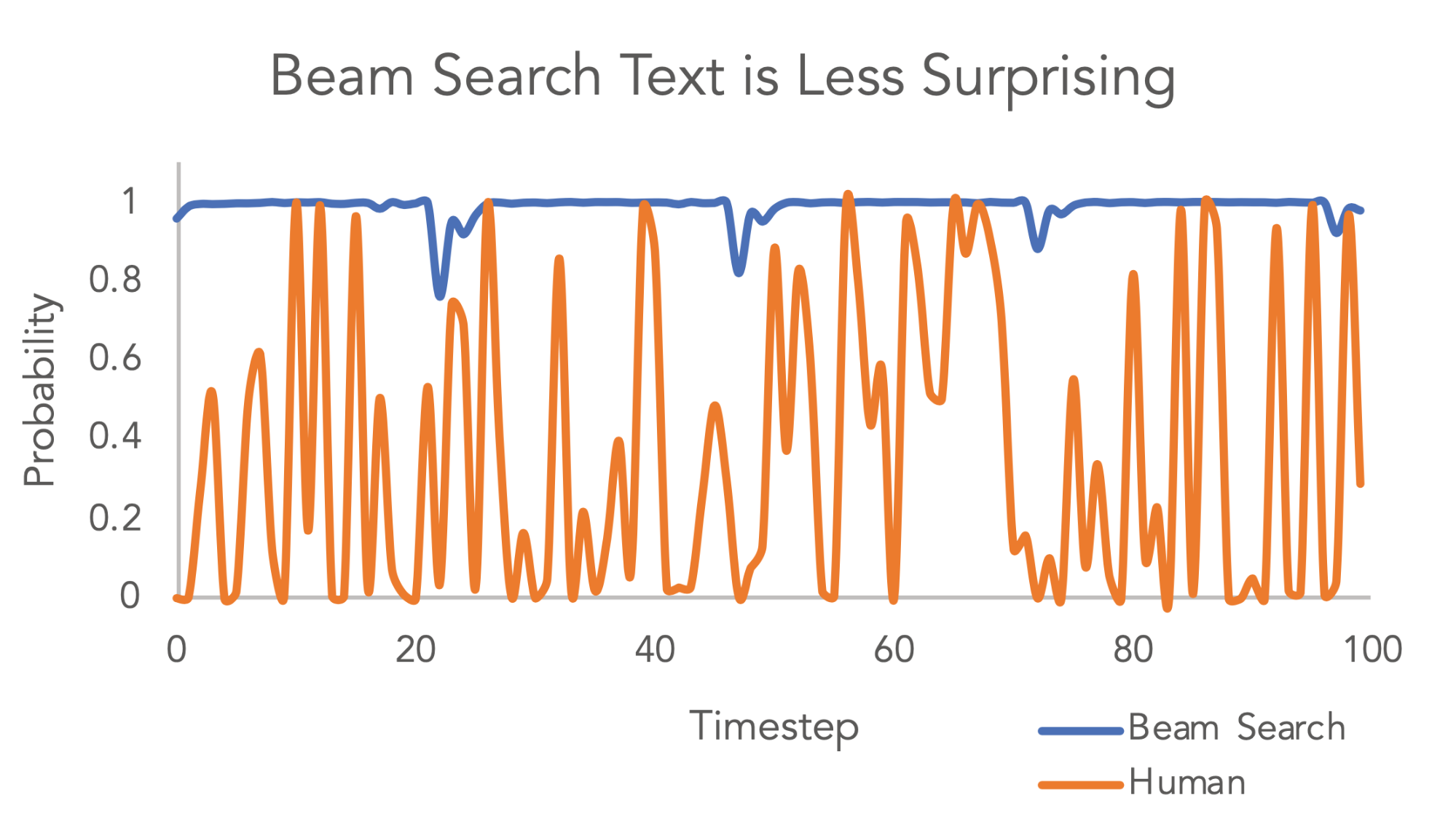
Anthropic conducted an experiment where Claude agents acted as digital barterers, successfully negotiating 186 deals totaling over $4,000. Participants found the deals fair, with nearly half expressing willingness to pay for such a service. The experiment highlighted that while model quality, such as Opus versus Haiku, significantly impacted deal outcomes, human participants did not perceive this difference. AI

IMPACT Demonstrates potential for AI agents in complex negotiation and commerce, suggesting future market viability.